Quantum Universe
Cluster of ExcellenceQuantum Universe
Photo: UHH/Denstorf
26 June 2025
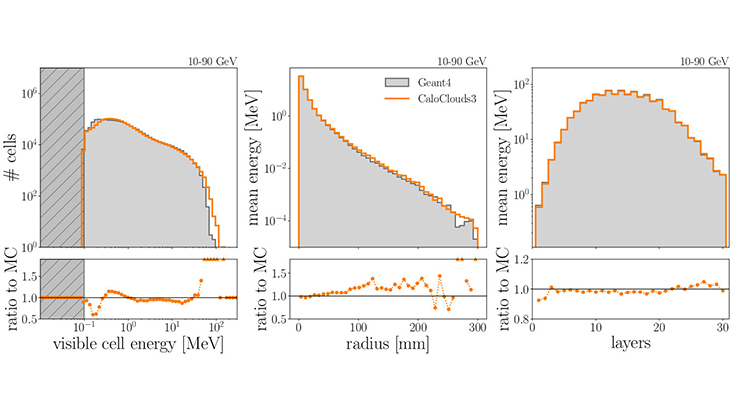
Photo: DESY
Detectors at future colliders promise beautiful highly-granular images of particle collisions. To make use of this data, simulating a vast number of events with high precision is necessary. At the Cluster of Excellence Quantum Universe, bleeding edge Generative Machine Learning (ML) models that meet the strict requirements for collider simulation and replicate the detector response with an inversion of entropy have been explored, and distilled to reveal their potential at a dramatically reduced computing time compared to standard simulation methods.
Much of life is an attempt to reverse entropy one way or another, which makes it both magical and sensible that teaching an ML model to reverse entropy works well. This is how a diffusion model generates new data. Beginning with a cloud of randomness, the diffusion model incrementally rearranges the points to resemble an example in the training set. The "Stable Diffusion" model inverts the entropy process to create beautiful images, such as imaginary landscapes, stylized portraits, or cats. (figure 1)
Figure 1: Step by step, entropy is removed from the 3D point cloud creating a cat. (Credits: DESY)
Collider physics heavily relies on very large simulated data sets. Theories often predict changes in the particle interactions, which cannot be directly observed. Instead, researchers simulate the observables expected in the detector from those theoretical predictions. Enough simulation is needed to prevent statistical errors from dominating the final analysis. Many analyses are needed, and luminosities are always rising, so a vast amount of simulation is required. Of all the steps in the simulation chain, detector simulation is the slowest.
Geant4 is the gold standard for detector simulation in particle physics, accurately representing particle interactions in matter. Strongly established and well maintained, Geant4 is trusted by the community. So perhaps unsurprisingly, substituting this with generative ML attracts controversy. However, collider physics has required simulation optimizations for a long time, such as parametrized approximations of energy depositions in the detector or ‘frozen showers’. Compute time is almost always a limiting factor. Such approximations were well understood, but imprecise, and only acceptable in places. Using generative ML, fast clones of Geant4 can surpass these approximations, improving analysis results while offering accuracy in more of the parameter space. More widespread substitution of Geant4 is not only faster, but also more sustainable, meeting our scientific goals with respect for our impact on the planet.
Most generative architectures predict a grid of fixed size, representing the detector readout as a 3D image. Often readouts are sparse, so time is wasted simulating empty space. Diffusion models don't need to predict images. The input points can represent hits, rather than pixel values, such that the model only records non-empty space. This is a major advantage, particularly for the high granularity calorimeters expected in future colliders.
The CaloClouds model was developed to showcase this (figure 2). As always, there is a catch: At the beginning of training a diffusion model, there is an example of the points in the distribution to model. Adding noise, a little at a time, leads to creating a sequence between each training example and a cloud of uniform randomness. Then the model learns to remove the noise, again a little at a time, until it can walk all the way back to something that looks like a training example. Many little steps add up to a lot of operations and the first CaloClouds model was only 20% faster than Geant4 on CPU. CaloClouds could gain some ground with a GPU, however, innovation was needed to become competitive with other generative solutions.
Figure 2: Step by step, entropy is removed from the 4D point cloud, points having 3 spatial dimensions plus energy, creating a properly described photon shower. (Credits: DESY)
Like distilling vodka, distilling a model compresses it into something more potent. For a diffusion model, this means turning the input cloud to the target in a single step. At the time of writing, "Deep-seek" has made headlines for being a highly successful distillation of other models. Deep-seek was trained using input and output pairs created by complex models such as ChatGPT. The complex model has already learnt a good mapping between input and output, which has less noise than the original training data. The heavy lifting of interpolation and extrapolation is already done, the complex model provides a smooth continuum of examples. With this guidance, the distillation model learns a simpler task, allowing a simpler design.
CaloClouds was distilled to CaloClouds II before Deep-seek had been released, and the strategy was rather unmapped. Further verification tests ensured the model still reproduced the physics; the article picture showcases basic examples. Additionally, the minimum size of the model was systematically investigated. The outcome was excellent; CaloClouds II is now 46 times faster than Geant4 on CPU, and nearly 2 thousand times faster on GPU. It delivers all the power and flexibility of its predecessor with leading edge speed. With this major challenge overcome, diffusion models offer ideal fast simulation for future high granularity calorimeters.

