Quantum Universe
Cluster of ExcellenceQuantum Universe
Photo: UHH/Denstorf
14 May 2025
Photo: Valentina Guglielmi
What do you do when you would like to play the newest computer game on your old computer, but the game is too demanding for your hardware? You own the previous version of the game, and it was fun, but over the years it has grown long in the tooth and is outdated. If you cannot afford to buy a new computer, you may not be able to enjoy the new game and you may well be stuck with the old version. At a much larger scale, a similar problem exists at the particle accelerator Large Hadron Collider (LHC).
The experimental collaborations at the LHC are operating some of the largest scientific computing infrastructures in the world, but we are still limited by the available computing resources. The high computing demands come from the need to process the collision data recorded by the four detectors and to produce detailed simulations of the underlying physics. Only by comparing the recorded data with expectations from simulations based on the current best understanding of the quantum world, can we gain knowledge and improve our description of nature. After achieving a breakthrough, updating all simulations to reflect this progress is necessary to allow for new insights.
With the successful operation of the LHC, more data is being recorded every day by the experimental collaborations, which also means that the demand for simulated data increases by the day. Current estimates predict that about 150 billion need to be simulated per year after the High-Luminosity LHC begins operation in 2029. Even with an assumed increase in our computing resources, following our past experience and together with expected technology improvements, the shortfall between needs and future resources will be a factor of 4 in CPU and a factor of 7 in disk storage. However, for scientists, being stuck with the old simulations is not an option because it jeopardizes future research capabilities. A solution that enables researchers to use the newest physics models with the limited resources available is essential.
This is where new methods based on machine learning (ML) can help. In the last few years, ML methods have been developed to change the properties of simulated samples so that they are equivalent to samples simulated with different parameters or different underlying models. The CMS Collaboration has employed one of these methods and studied how well it works when applied to simulated samples used in data analyses. The outcome: A given sample can mimic another sample with high accuracy in all relevant aspects.
The significance of this approach is that now it is now sufficient to have just one single simulated sample, and the ML algorithm can emulate different simulations from it. The detector simulation and event reconstruction have to be computed only once for this single sample. “Since these two steps require about 75% of the computing resources for each simulated sample, the gain is considerable”, says Valentina Guglielmi, a doctoral researcher at DESY and actively contributing to the Cluster of Excellence Quantum Universe and lead author of the study. “Imagine that you run the old version of your computer game on your old hardware, but it looks and feels like the newest version. The ML model simulates the new game in the background, without a performance penalty. Since there is no visible difference in sound and graphics, you are actually playing the new version of the game without the need to buy a new computer.”

Photo: Valentina Guglielmi
Here is how the new method works: First, a large sample of simulated data is produced using a given physics model. This sample undergoes a detailed detector simulation, which is computationally expensive. Then, additional, smaller samples are produced based on different models in order to train the ML algorithm. Unlike the central sample, these do not require the detailed detector simulation and event reconstruction. The ML model is trained to compute weights for each simulated event, which can then be applied to the central simulated sample to imitate the alternative simulations. This new study shows that the ML method can be applied effectively to simulated samples of top quark pair production. It is essential to produce only one sample instead of several, where the additional samples are typically used to compute systematic uncertainties in our measurements. This significantly reduces the computational cost.
The ML approach has also been applied to mimic a more accurate simulation program from the less accurate central sample, thus showing the possibility of updating our existing simulations to reflect new theoretical progress. This result is shown in Figure 1, which shows distributions in the transverse momentum of top quarks produced at the LHC, from two different simulation programs (named NLO, for next-to-leading order, and NNLO for next-to-next-to-leading order). In the transverse momentum distribution, the more accurate NNLO simulation differs from the NLO simulation by up to 20%. Applying the ML algorithm to the NLO sample, the result mimics the NNLO sample very accurately. The huge advantage of this new method is that it can change all relevant features simultaneously, which we have never been able to achieve with other methods.
“The developed method is versatile and user-friendly, making it straightforward for researchers to integrate into their analyses,” explains Valentina Guglielmi. This innovative approach helps to reduce the necessary computing resources to produce simulated samples, crucial for the future success of the LHC research program.
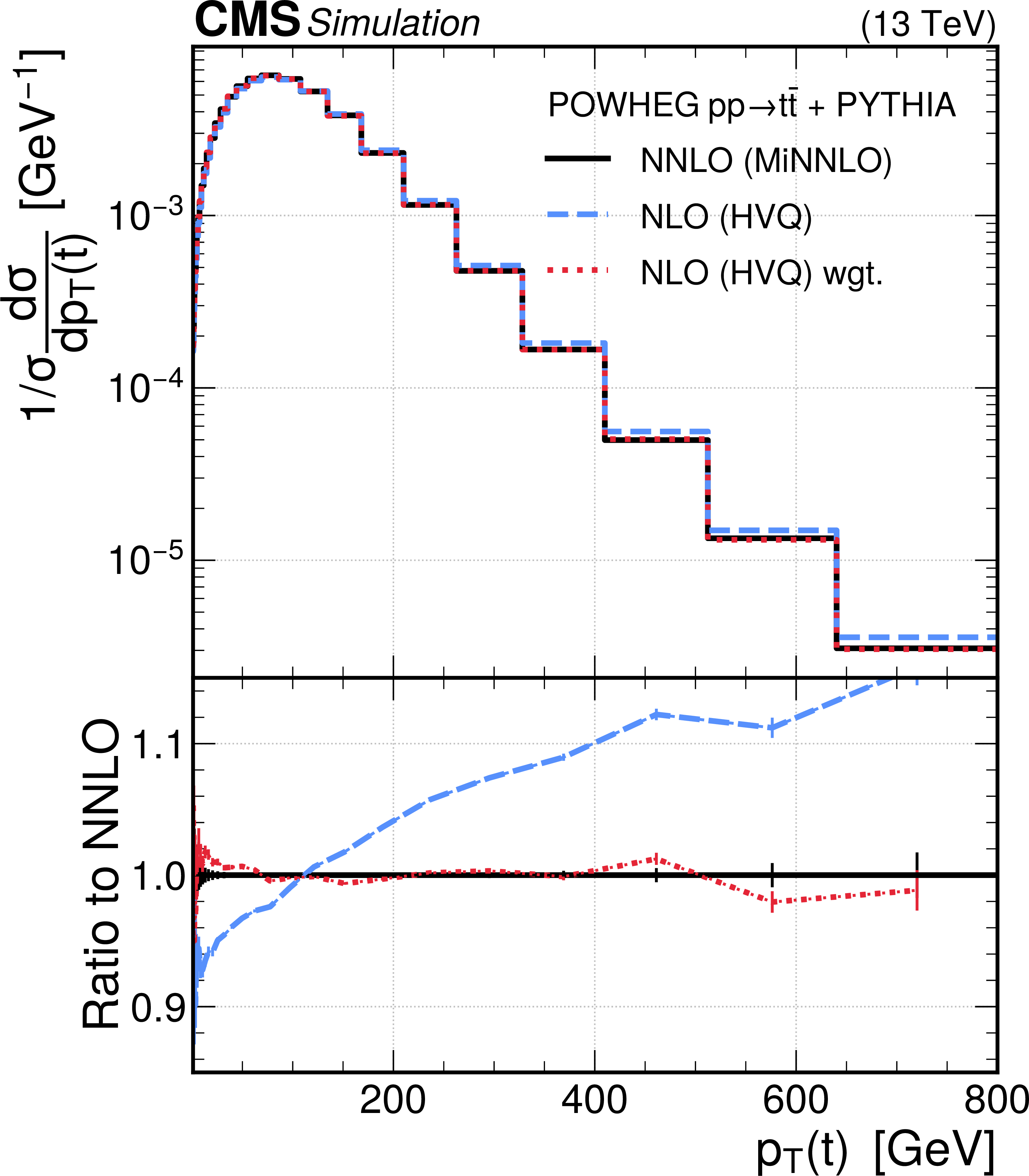
Figure 1: Transverse distribution of top quarks simulated from less accurate NLO (blue) and more accurate NNLO (black). The ML approach (red) re-weights the NLO sample to accurately mimic the NNLO, Credits: CMS Collaboration
Adapted from CMS Briefing "Game Changer: Machine Learning Transforms LHC Simulations"

